做人脸检测已经一段时间了,临近毕业想想工作后估计应该不会有太多时间再来搞这个,下面抽取了毕业论文的第二章对以前看过的论文进行了总结,写成了下面的综述,涵盖到比较多的方法,希望对看到这篇文章的研究者会有所帮助。
自 2001 年 Viola 和 Jones [1] 将级联分类器的概念引入到人脸检测领域, 其后发展起来的人脸检测算法被设计成更好地处理多角度检测, 遮挡, 模糊等问题 [15][16]。 这些算法主要有三大类分支, 第一类是基于级联结构及其改进的算法, 如文献 [6][17][18] 中所提到的人脸检测方法在特征表达, 分类器构造, 运行速率, 多角度模板均进行了大量的改进。级联分类使得检测时非人脸区域可以快速排除, 从而获得了高效的运行速率。 这类人脸检测系统已经被广泛地运用于银行, 摄像头监控系统, 移动手机, 网络社区等。第二类是基于弹性不变模型 (DPM) [8] 的算法, 这类算法的模型包含若干组成部分, 而这些组成部分通过位置关系进行约束得到整体人脸的检测模型, 这类模型对人脸的形变及遮挡具有很好的适应性和很高的灵活性。 文献 [9]在得到组成部分的同时进行了人脸标定点, 人脸角度的检测。 第三类是基于神经网络的人脸检测算法, 神经网络主要由若干层卷积层, Pooling 层, 全连接层组成, 对图像提取的卷积网络特征对人脸有更高层次的表达性。 文献 [19] 通过训练多个神经网络模型来提高人脸检测效果。 由于局部最优问题 [20] 及训练困难, 过去研究者们更多地进行前两类算法的研究。 随着近年来深度卷积网络的成功, 神经网络算法重新被研究者们所重视。
本文首先详细介绍了基于级联分类器和弹性不变模型的人脸检测算法, 以及当前研究中对这些算法进行的改进。 接着, 简单阐述了神经网络及深度学习的历史, 然后详细介绍了基于神经网络的人脸检测算法以及近来的发展。 最后,本文小结了这三类方法的异同。
基于级联分类器的人脸检测算法
基于级联分类器的人脸检测算法扩展了 Viola 和 Jones [1] 最初提出的级联结构 (cascade structure), 其核心思想就是, 让负样本通过所有弱分类器 (weak classifiers) 的概率尽可能低,同时保证正样本通过每层由弱分类组成的强分类器(strong classifier)的最低概率, 达到高检测率低错检率的目的。 在图 2-1 中, 以决策树 (CART) 作为弱分类器为例, 图2-1(a)表示输入的图像, 图2-1(b-g)绿色矩形表示经过若干层后剩下的候选目标区域, 可以看出, 经过 $ 20 $ 层后剩下的候选目标区域集中覆盖在人脸所在的区域,这些区域然后继续被送到后续的分类器。 图2-1(h)表示经过所有层后最终的人脸检测结果, 可以观察到人脸区域可以顺利通过这些弱分类器, 而负样本则被基本过滤了。
![图2-1 在lena图上使用NPDFace人脸检测器 [[21]](#21) 进行人脸检测。 绿色矩形为经过不同层数所剩下的候选人脸区域](/2016/06/07/人脸检测算法概述/1.png) 图2-1 在lena图上使用NPDFace人脸检测器 [21] 进行人脸检测。 绿色矩形为经过不同层数所剩下的候选人脸区域
图2-1 在lena图上使用NPDFace人脸检测器 [21] 进行人脸检测。 绿色矩形为经过不同层数所剩下的候选人脸区域Viola 和 Jones 成功将 AdaBoost 机器学习方法 [22] 引入到人脸检测中, 在文献 [1][2] 中采用 Haar 特征进行人脸特征表达, 特征表达简单, 如图 2-2(a)。 提出的积分图概念, 进一步加快了特征提取效率, 然后通过 $ 20 $ 层 AdaBoost 分类器快速过滤掉非人脸区域。 经典的级联 AdaBoost 算法采用单层决策树(stump)作为弱分类器。 训练时, 弱分类器的加权错误为:
$$ \epsilon_i = min \sum_j w_j|h(x_i)-y_i| $$
其中, $ \epsilon_i $ 为第个弱分类器的分类错误, $ w_j $ 为训练样本的权重,$ y_i \in [1,0] $ 表示样本为人脸与非人脸, $ h(x_i) $ 为当前弱分类器对样本 $ x_i $ 的输出得分。 每次训练得到一个弱分类器都会对训练样本的权重重新进行调整, 降低分类正确的样本的权重, 分类错误的样本则与之相反, 从而使得后续的弱分类器针对分类错误的样本。
检测时, 窗口 $ x $ 经过由若干个弱分类器组成的 AdaBoost 强分类器输出为:
$$ C(x) = \begin{cases} 1, \sum_{i}^{T} \alpha_i h_i(x) \gt \eta \\ 0, otherwise \end{cases} , 其中 \alpha_i = log\frac{1-\epsilon_i}{\epsilon_i} $$
其中 $ \eta $ 为保证负样本通过该强分类器概率至多为 $ p_f $, 正样本通过概率至少为的阈值 $ p_t $(如 $ p_f = 0.5, p_t = 0.95 $), 经过 $ 20 $ 层后, 正、负样本通过所有层的概率分别为 $ 0.95^{20} > 0.9, 0.5^{20}< 10^{-6} $。
 (a)Haar 特征示例。灰色矩形内像素和减去白色矩形内像素和为 Haar 特征计算方式,文献 [1][2] 采用灰度图进行计算
(a)Haar 特征示例。灰色矩形内像素和减去白色矩形内像素和为 Haar 特征计算方式,文献 [1][2] 采用灰度图进行计算 (b)多通道特征,从左到右,从上到下依次为LUV彩色通道,梯度响应图、在六个方向上的梯度响应图
(b)多通道特征,从左到右,从上到下依次为LUV彩色通道,梯度响应图、在六个方向上的梯度响应图图2-2 人脸特征
级联 Adaboost 人脸检测算法以其简单的特征, 高效的实时性而广受欢迎。 但其对人脸进行描述的 Haar 特征对人脸的角度、光照变化、模糊、表情变化等复杂情况适应性较差。 文献 [4][5] 进一步扩展了 Haar 特征以适应更多不同的人脸模式。 针对 Haar 特征表达性差的问题, 文献 [18][23] 提出了基于更强表达性的SURF [25] 特征的人脸特征,使用 CPU 并行处理技术及积分图加速特征计算。 人脸特征中纹理特征是一种比较重要的特征, 文献 [26] 指出纹理分布比纹理强度更有利于分类, 改进了纹理特征 LBP [27] 来进行人脸表达。 人脸检测算法大多数从灰度图特征提取, 彩色通道由于特征提取困难而被忽视, 而人脸轮廓特征表达能力强, 文献 [28] 创造性地引入了文献 [29] 中针对行人检测而提出的基于 LUV 颜色通道及 HOG 特征 [30] 的多通道特征到人脸检测领域, 运用积分图加速特征计算, 如图 2-2(b)所示。 文献 [17] 则从文献 [31] 得到灵感,去除了文献 [28] 积分图的操作, 在特征选择时直接从多通道特征图中选取, 进一步简化了特征提取过程, 并取得不错的效果。
除了对特征的改进, 级联结构同样也成为研究者们关注的重点。 文献 [5] 指出 Gentle Adaboost 比原来的 Discrete Adaboost 算法分类效果更好, 深层的决策树需要更少的级联层数。 训练时正样本要尽可能地可以通过弱分类器, 因此弱分类器对损失函数的影响比负样本远远要大, 文献 [32] 通过降低弱分类器对正样本的输出得分, 从而使得后续的弱分类器更好地针对正样本进行训练。 在文献 [3] 中将每层强分类器得分改进为当前层强分类器与前面强分类器的累积和, 并将对分类效果无影响的已训练的弱分类器进行了移除, 鲁棒性更强。 文献 [24] 进一步将强分类器简化为弱分类器, 经过一个弱分类器则进行一次判断, 每个弱分类器的输出为当前弱分类器与之前弱分类器的累加。 单个决策树区分能力较弱, 文献 [18] 使用逻辑回归分类器作为每层的弱分类器, 阈值依据曲线的 AUC(area under curve) 大小来设置, 增强了正样本通过的概率同时大大降低了负样本通过的概率, 减少了检测的阶段数目。 文献 [33] 通过推导提出了级联结构的两种一般化表示方式, 针对弱分类器叠加可能导致的局部最优问题, 提出了在强分类器上任意层动态加入最优弱分类器的算法, 尽可能保证了全局最优, 减少了弱分类器数目。
结合其他领域的算法为基于级联结构的人脸检测算法的未来改进提供了思路。 文献 [10][11] 结合文本检索技术, 弱分类器基于人脸词袋 (face examplar), 每一个弱分类器输出图像的人脸响应图, 累积这些响应图得到最后的人脸检测结果。相邻窗口的得分有一定的联系性, 单独处理每个窗口可能导致正样本过早地被去除, 在行人检测领域, 文献 [34] 在仿照人的神经递质提出了带有激活与抑制结构的人脸检测算法, 使得高得分附近的窗口得到增强, 而低得分附近的窗口得到抑制, 进一步提高检测的召回率和准确率, 为人脸检测算法提供了新思路。 非约束场景人脸形变较大, 人脸对齐方法 [35]-[38] 可以对人脸部位进行局部拟合得到人脸的特征点位置, 文献 [39] 创新性地将人脸检测与对齐方法进行结合, 在学习每棵决策树的同时, 将人脸特征点进行回归学习, 用人脸特征点指导分类器特征的选取。
基于弹性不变模型的人脸检测算法
在非约束场景下, 人脸的表情、角度所带来的形变较大, 遮挡及光照变化会引入噪声。 基于级联结构的人脸检测算法往往是对预先学习到的位置提取分类特征, 对遮挡等噪声适应性较差。 另外,这些方法将不同表情、不同角度的人脸当成多个子类处理, 在预测时决策树每个节点将人脸划分到模式相同的簇 (batch) 提取特征, 对于形变过大的人脸, 决策树可能会将其划分到错误的节点上, 将其过早地过滤掉。
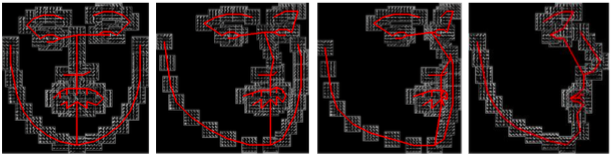 (a)文献 [9] 所使用的混合树模型示例
(a)文献 [9] 所使用的混合树模型示例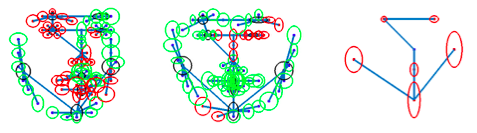 (b)文献 [40] 带遮挡特征点的人脸弹性模型示例。 红色为遮挡特征点, 绿色为可见特征点, 右图为人脸尺度较小时的模型
(b)文献 [40] 带遮挡特征点的人脸弹性模型示例。 红色为遮挡特征点, 绿色为可见特征点, 右图为人脸尺度较小时的模型图 2-3 弹性不变模型示例
基于弹性不变模型 [7][8] 的人脸检测算法可以有效解决如遮挡、光照变化、表情变化、角度不一的问题。 这类方法将人脸定义为人脸不同部位 (parts) 的组合, 如鼻子、眼睛、嘴、耳朵等, 这些不同的部位通过“弹簧 (spring)”进行组合, 如图 2-3 所示。 这些人脸部位由非监督或者监督算法进行训练得到。 Latent SVM 分类器被训练来在人脸上找到这些部位及他们间的几何关系, 因此该类方法可以适应人脸的形变。 又由于是对局部部位进行特征提取, 因此, 这类方法还能检测到有部分遮挡的人脸 (如图 2-4 所示), 对人脸遮挡情况有很好的鲁棒性。
人脸检测算法需要的训练数据往往比较大, 在文献 [9] 中将人脸定义为若干个混合树模型, 每个子节点均由一个父节点关联, 只需要几百张标记有特征点位置的人脸训练数据就可以学习到不同模式的人脸, 而且在检测人脸的同时判断了人脸的角度及标定点的位置。 文献 [40] 在文献 [9] 基础上扩展了混合树模型来处理遮挡, 将人脸部位进行分级, 如眼睛、鼻子、嘴巴为一级, 这些位置附近的特征点为第二级, 如图 2-3(b)。 训练时随机生成带遮挡的人脸, 检测时当人脸某个部位被遮挡时, 对分类无效。 尽管这些变形采用了更加复杂的策略来处理人脸变形及遮挡, 文献 [28] 通过构建多个不同角度、不同尺度的弹性不变模型分别检测特定人脸, 取得了比文献 [9][41] 中复杂变形更好的效果。
 图 2-4 左图为文献 [9] 检测结果。 右图为文献 [40] 检测结果, 红色为遮挡人脸部位
图 2-4 左图为文献 [9] 检测结果。 右图为文献 [40] 检测结果, 红色为遮挡人脸部位基于弹性不变模型的人脸检测器计算量大, 主要由于:
另外, 基于弹性不变模型的一些算法 [9][40] 需要训练数据集包含人脸特征点的标定, 建立这些数据集需要消耗大量人力物力。
基于神经网络/深度学习的人脸检测算法
卷积神经网络
传统人脸检测算法需要人工设计的特征, 需要大量专业领域知识, 线性分类器对人工提取的特征进行分类, 只能把样本分成简单的区域。 神经网络核心是通过使用自主学习过程来得到良好的特征 [43]。 由于梯度下降方法可能使得网络陷入局部最小值, 在 20 世纪 90 年代神经网络方法被研究者们所抛弃。 近年来,随着理论研究及实践表明, 大网络总是会得到差不多的解, 局部最小值并不会对网络整体性能造成很大影响 [20]。 同时, ReLU 非线性函数 [44] 的提出解决了梯度弥散问题, dropout 思想 [45] 的提出一定程度上解决了网络过拟合问题, 预训练 (pre-trained) 过程可以使得网络训练的效果更好的发现 [43], 使得神经网络学习算法重新被研究者们关注。
卷积神经网络重新被计算机视觉团队及研究者们所重视是在 2012 年的百万图像规模数据竞赛 ImageNet 后, 该数据集包含 $ 1000 $ 个类别的物体, 深度卷积神经网络算法几乎比当时其他方法降低了 $ 50\% $ 的错误率 [43]。 卷积神经网络被设计成更容易地处理图像等多维数据, 其主要包含卷积层、归一化层、pooling层。
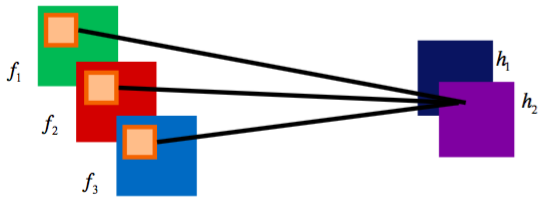 图2-5 卷积层示例, 其中, $ f_1, f_2, f_3 $为前一层的特征图,$ h_1, h_2 $ 为下一层输出的特征图
图2-5 卷积层示例, 其中, $ f_1, f_2, f_3 $为前一层的特征图,$ h_1, h_2 $ 为下一层输出的特征图图像像素相邻位置具有很强的相关性, 对这些位置提取的特征表达性更强, 卷积神经网络使用卷积层实现这一功能, 卷积层如图 2-5 所示。 卷积层包含一组卷积核, 每个卷积核作用于前一层的特征图上, 上一层特征图的加权和得到下一层的特征图, 卷积核类似滤波操作。 卷积层是一种局部连接, 大大减少了全连接 (fully connected) 层的参数数目。 利用 ReLU 作为激活函数, 则卷积层特征图输出为:
$$ h_i = max(0, \sum_k f_k*w_i ) $$
其中为 $ w_i $ 当前层第 $ i $ 个卷积核, $ f_k $ 为前一层第 $ k $ 个特征图,$ h_i $为当前层第 $ i $ 个特征图输出。
归一化层往往接在卷积层后, 是对卷积层得到的特征图的归一化, 去除光照、线性噪声等外界因素的影响, 增强特征表达的适应性。
Pooling 层是为了让卷积层提取的特征更加鲁棒。 该层计算特征图局部最小邻域的最大值 (max-pooling) 或者平均值 (avg-pooling), 一方面对卷积层得到的特征进行了降维, 另一方面减少了噪声干扰, 使得特征更加突出。
基于神经网络/深度学习的人脸检测算法
基于神经网络的人脸检测算法历史悠久 [46]-[53]。 文献 [46][47] 基于浅层卷积神经网络训练了一个两阶段人脸检测系统, 在第一个阶段, 训练了一个网络粗略定位人脸的位置, 第二个阶段则使用另外一个网络来验证这些位置是否包含人脸, 并调整了检测框。 单个网络可能得到局部最优值, 文献 [48] 在相同的训练数据集上分别采用不同的随机初始化参数训练了若干个浅层神经网络, 以此来避免该问题。 检测时图像被缩放到多个尺度上, 每个网络对图像输出人脸位置, 来自这些浅层神经网络的检测结果经过一系列的步骤进行融合, 得到了比单个网络更好的结果。
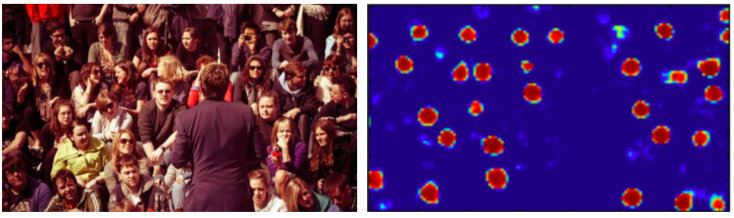 图2-6 文献 [13] 网络输出的人脸概率分布图示例。 左图为原图, 右图为其概率分布图, 红色区域表示人脸出现概率高的区域, 蓝色则表示人脸出现概率低的区域(使用了网站https://github.com/guoyilin/FaceDetection_CNN 的模型)。
图2-6 文献 [13] 网络输出的人脸概率分布图示例。 左图为原图, 右图为其概率分布图, 红色区域表示人脸出现概率高的区域, 蓝色则表示人脸出现概率低的区域(使用了网站https://github.com/guoyilin/FaceDetection_CNN 的模型)。更深的网络拥有更好的人脸检测性能。 文献 [49] 训练了单个浅层卷积神经网络来进行人脸检测, 该网络包含两层卷积层与 Pooling 层, 并通过权重共享将网络参数减少。 与过去方法只将人脸小范围旋转度进行训练集扩充不同, 在训练时, 该算法将人脸数据集左右旋转度及亮度归一化处理得到更多训练样本, 使得网络更加适应人脸的旋转和亮度变化。 文献 [53] 与文献 [49] 一样使用了两个卷积层和 Pooling 层, 不同的是创造性在浅层神经网络里引入了多任务损失函数进行学习, 该函数包含了两部分, 一部分为人脸检测的损失函数, 第二部分是人脸角度预测的损失函数。 通过这种方式, 神经网络不仅能检测到人脸, 还能预测出人脸所在的角度。
随着深度学习的重新兴起及 GPU 硬件的支持, 基于神经网络的人脸检测算法所使用的网络沿着更深更广的趋势发展。 文献[13] 在文献 [49] 的基础上, 使用 GPU 进行训练学习了更深的神经网络 AlexNet [12][14], 其网络拥有五层卷积层和两层 Pooling 层。 与文献 [49] 相比, 最大不同在于:
- 网络更深更广, 使用了 ReLU 非线性函数、dropout 函数进行训练;
- 使用了在超大型 ImageNet 数据集上预训练好的模型 AlexNet, 其模型本身初始化的权值拥有意义;
- 修改了全连接层使其可以输出每个位置上的人脸响应, 通过扫描窗口得到人脸的检测结果, 如图 2-6 所示;
- 使用了更大的数据集进行训练, 随机采样了 200,000 张人脸及 20,000,000 个负样本, 并为了保持训练数据均匀, 每批 (batch) 使用 32 个正样本及 96 个负样本进行训练。
文献 [13] 使用单一模型取得了与基于级联结构和弹性不变模型的人脸检测算法相似的检测效果。 多通道特征在人脸表示方面有比 HOG, SURF 等特征更强的表达性, 深度卷积网络学习到的人脸特征图是对人脸的高层次的抽象表示, 而分布式特征表示方式 (如图 2-7) 使得网络的权重能学习到人脸有显著特征的部位, 即能提取到局部特征。 文献[54] 进一步扩展了多通道特征为深度卷积网络学习到的特征图, 实验表明, 这些特征图比多通道特征有更好的表达性。
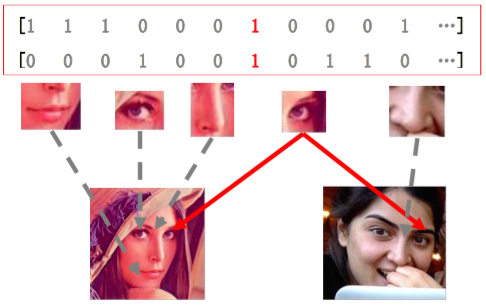 图 2-7 分布式特征表示方式
图 2-7 分布式特征表示方式遵循 coarse-to-fine 原则是当前基于深度卷积网络的人脸检测算法的重要发展趋势。 基于级联结构的人脸检测算法 [39] 在检测人脸同时进行人脸标定点拟合来取得更好人脸检测框位置, 文献[55] 则提出了基于级联结构的卷积网络算法。 该算法同样在人脸检测时考虑到人脸矫正以获得更高性能, 共有三个阶段,每个阶段均包含有一个的检测网络, 后一阶段比前一阶段网络要更大, 分类性能更强。 每个阶段的网络输出会经过尺度、长宽、位置调整产生若干个候选区域再次进行检测, 保留得分比较好的区域作为下一阶段的输入, 以此将这些区域逐渐调整到更精确的人脸位置上。 Yang等人[56] 采用与文献 [46] 相似的策略, 提出了双阶段人脸检测器, 但深度要更加深, 对每个人脸部位生成响应图过滤得分过低的人脸候选区域, 如图 2-8, 并通过接在其后的检测网络得到对候选区域进行更加严格的分类与调整。
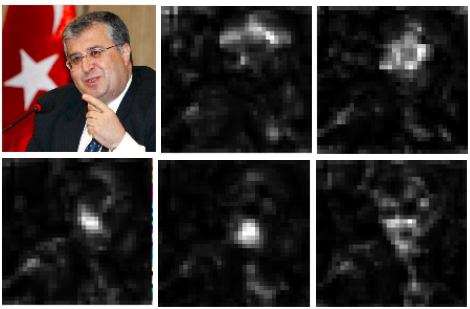 图2-8 人脸部位响应图。 左上角为原图,从左到右从上到下分别为该图头发、眼睛、鼻子、嘴巴、下巴的响应图
图2-8 人脸部位响应图。 左上角为原图,从左到右从上到下分别为该图头发、眼睛、鼻子、嘴巴、下巴的响应图小结
本文从三个分支上概述了人脸检测的算法。特征表达方面, 基于级联结构及弹性不变模型的人脸检测算法多是人工设计的, 而神经网络/深度学习则是通过网络学习人脸的特征图, 具有分布式特征表示方式。 尽管各个分支的处理方法不一, 但可以看到这三类方法的本质都是一样的, 都是提取人脸特征进行分类, 检测出图像中所有人脸出现的位置。 这三者基本的不同点在于, 基于级联结构的算法考虑到了图像中负样本数目庞大的因素, 在检测时把负样本更早地去除提高了整体检测的效率。 基于弹性不变模型的算法针对人脸各部分局部特征响应寻找图像中的人脸。 基于神经网络/深度学习的算法自主学习人脸局部及整体特征。
参考文献
- P. Viola, M. Jones. Rapid object detection using a boosted cascade of simple features[C], IEEE Conference on Computer Vision and Pattern Recognition, 2001, I-511~I-518
- P. Viola, M. Jones. Robust real-time face detection[J]. International Journal of Computer Vision, 57(2), 2004, 137-154
- R. Xiao, L. Zhu, H. Zhang. Boosting Chain Learning for Object Detection[C], IEEE International Conference on Computer Vision, 2003, 709~715
- R. Lienhart, J. Maydt. An Extended Set of Haar-like Features for Rapid Object Detection[C], IEEE International Conference on Image Processing, 2002, I-900~I-903
- R. Lienhart, A. Kuranov, V. Pisarevsky. Empirical Analysis of Detection Cascades of Boosted Classifiers for Rapid Object Detection[C], Pattern Recognition, Springer, 2003, 297~304
- M. Jones, P. Viola. Fast multi-view face detection[C], IEEE Conference on Computer Vision and Pattern Recognition, 2003
- P. F. Felzenszwalb, D. P. Huttenlocher. Pictorial Structures for Object Recognition[J], International Journal of Computer Vision, Vol. 61, No. 1, 2005, 55~79
- P. F. Felzenszwalb, R. B. Girshick, D. McAllester, D. Ramanan. Object Detection with Discriminatively Trained Part-Based Models[J], IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 32, No. 9, 2010, 1627~1645
- X. Zhu, D. Ramanan. Face detection, pose estimation, and landmark localization in the wild[C], IEEE Conference on Computer Vision and Pattern Recognition, 2012, 2879~2886
- X. Shen, Z. Lin, J. Brandt, Y. Wu. Detecting and Aligning Faces by Image Retrieval[C], IEEE Conference on Computer Vision and Pattern Recognition, 2013, 3460~3467
- H. Li, Z. Lin, J. Brandt, X. Shen, G. Hua. Efficient Boosted Exemplar-based Face Detection[C], IEEE Conference on Computer Vision and Pattern Recognition, 2014, 1843~1850
- A. Krizhevsky, I. Sutskever, G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks[C], 2012, 1097~1105
- S. S. Farfade, M. Saberian, L. Li. Multi-view Face Detection Using Deep Convolutional Neural Networks[C], 5th ACM International Conference on Multimedia Retrieval, 2015, 643~650
- R. Girshick, J. Donahue, T. Darrell, J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation[C], IEEE Conference on Computer Vision and Pattern Recognition, 2014, 580~587
- N. Markus, M. Frljak, I. S. Pandzic, J. Ahlberg and R. Forchheimer. A Method for Object Detection Based on Pixel Intensity Comparisons Organized in Decision Trees[J], arXiv preprint arXiv:1305.4537, 2013
- L. Shengcai, A. K. Jain, and S. Z. Li. Unconstrained face detection, Technical report, Michigan State University, Dec.2012
- B. Yang, J. Yan, Z. Lei, S. Z. Li. Aggregate channel features for multi-view face detection[C], IEEE International Joint Conference on Biometrics, 2014, 1~8
- J. Li, Y. Zhang. Learning SURF Cascade for Fast and Accurate Object Detection[C], IEEE Conference on Computer Vision and Pattern Recognition, 2013, 3468~3475
- H. A. Rowley, S. Baluja, T. Kanade. Neural network-based face detection[C], IEEE Conference on Computer Vision and Pattern Recognition, 1996, 203~208
- Y. Dauphin, R. Pascanu, C. Gulcehre, K. Cho, S. Ganguli, Y. Bengio. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization[C], Neural Information Processing Systems, 2014, 2933~2941
- S. Liao, A. K. Jain, S. Z. Li. A Fast and Accurate Unconstrained Face Detector[J], IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 38, No. 2, 2016, 211~223
- Y. Freund, R. E Schapire. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting[J], Journal of computer and system sciences, Vol. 55, No. 1, 1997, 119~139
- J. Li, T. Wang, Y. Zhang. Face detection using SURF cascade[C], IEEE International Conference on Computer Vision, 2011, 2183~2190
- L. Bourdev, J. Brandt. Robust Object Detection Via Soft Cascade[C], IEEE Conference on Computer Vision and Pattern Recognition, 2005, 236~243
- H. Bay, A. Ess, T. Tuytelaars, L. Van Gool. Speeded-Up Robust Features (SURF)[J], Computer Vision and Image Understanding, Vol. 10, No. 3, 2008, 346~359
- J. Wu, N. Liu, C. Geyer, J. M. Rehg. C4 : A Real-Time Object Detection Framework[J], IEEE Transactions on Image Processing, Vol. 22, No. 10, 2013, 4096~4107
- T. Ojala, M. Pietikäinen, D. Harwood. A comparative study of texture measures with classification based on featured distributions, Pattern Recognition, Vol. 29, No. 1, 1996, 51~59
- M. Mathias, R. Benenson, M. Pedersoli, L. Van Gool. Face detection without bells and whistles[C], European Conference on Computer Vision, 2014, 720~735
- P. Dollár1, Z. Tu, P. Perona, S. Belongie. Integral channel features[C], British Machine Vision Conference, 2009, 91.1~91.11
- N. Dalal, B. Triggs. Histograms of Oriented Gradients for Human Detection[C], IEEE Conference on Computer Vision and Pattern Recognition, 2005, 886~893
- P. Dollár, R. Appel, S. Belongie, P. Perona. Fast Feature Pyramids for Object Detection[J], IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 36, No. 8, 2014, 1532~1545
- P. Viola, M. Jones. Fast and Robust Classification using Asymmetric AdaBoost and a Detector Cascade[C], Neural Information Processing Systems, 2002, 1311~1318
- M. Saberian, N. Vasconcelos. Boosting Algorithms for Detector Cascade Learning[J], Journal of Machine Learning Research, Vol. 15, No. 1, 2014, 2569~2605
- P. Dollár, R. Appel, W. Kienzle. Crosstalk Cascades for Frame-Rate Pedestrian Detection[C], European Conference on Computer Vision, 2012, 645~659
- S. Ren, X. Cao, Y. Wei, J. Sun. Face Alignment at 3000 FPS via Regressing Local Binary Features[C], IEEE Conference on Computer Vision and Pattern Recognition, 2014, 1685~1692
- X. Cao, Y. Wei, F. Wen, J. Sun. Face Alignment by Explicit Shape Regression[C], IEEE Conference on Computer Vision and Pattern Recognition, 2012, 2887~2894
- X. P. Burgos-Artizzu, P. Perona, P. Dollár. Robust face landmark estimation under occlusion[C], IEEE International Conference on Computer Vision, 2012, 1513~1520
- P. Dollár, P. Welinder, P. Perona. Cascaded Pose Regression[C], IEEE Conference on Computer Vision and Pattern Recognition, 2010, 1078~1085
- D. Chen, S. Ren, Y. Wei, X. Cao, J. Sun. Joint Cascade Face Detection and Alignment[C], European Conference on Computer Vision, 2014, 109~122
- G. Ghiasi, C. C. Fowlkes. Occlusion Coherence: Detecting and Localizing Occluded Faces[J], arXiv preprint arXiv:1506.08347, 2015
- J. Yan, X. Zhang, Z. Lei, S. Z. Li. Face detection by structural models[J], Image and Vision Computing, Vol. 32, No. 10, 2014, 790~799
- J. Yan, Z. Lei, L. Wen, S. Z. Li. The Fastest Deformable Part Model for Object Detection[C], IEEE Conference on Computer Vision and Pattern Recognition, 2014, 2497~2504
- Y. LeCun, Y. Bengio, G. Hinton. Deep learning[J], Nature, Vol. 521, No. 7553, 2015, 436~444
- X. Glorot, A. Bordes, Y. Bengio. Deep Sparse Rectifier Neural Networks[J], Journal of Machine Learning Research[J], 2011, 315~323
- G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, R. R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors[J], arXiv preprint arXiv:1207.0580, 2012
- R. Vaillant, C. Monrocq, Y. Le Cun. An original approach for the localization of objects in images[C], IEEE International Conference on Articial Neural Networks, 1993, 26~30
- R. Vaillant, C. Monrocq, Y. Le Cun. Original approach for the localisation of objects in images[J], Vision, Image and Signal Processing, Vol. 141, No. 4, 1994, 245~250
- H. A. Rowley, S. Baluja, T. Kanade. Neural network-based face detection[C], IEEE Conference on Computer Vision and Pattern Recognition, 1996, 203~208
- C. Garcia, M. Delakis. A Neural Architecture for Fast and Robust Face Detection[C], IEEE International Conference on Pattern Recognition, 2002, 44~47
- M. Delakis, C. Garcia. Training Convolutional Filters for Robust Face Detection[C], IEEE International Workshop of Neural Networks for Signal Processing, 2003, 739~748
- C. Garcia, M. Delakis. Convolutional face finder: a neural architecture for fast and robust face detection[J], IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 26, No. 11, 2004, 1408~1423
- S. Roux, F. Mamalet, C. Garcia. Embedded Convolutional Face Finder[C], IEEE International Conference on Multimedia and Expo, 2006, 285~288
- M. Osadchy, Y. Le Cun, M. L. Miller. Synergistic Face Detection and Pose Estimation with Energy-Based Models[J], Journal of Machine Learning Research, Vol. 8, No. 1, 2007, 1017~1024
- B. Yang, J. Yan, Z. Lei, S. Z. Li. Convolutional channel features[C], IEEE International Conference on Computer Vision, 2015, 82~90
- H. Li, Z. Lin, X. Shen, J. Brandt, G. Hua. A convolutional neural network cascade for face detection[C], IEEE Conference on Computer Vision and Pattern Recognition, 2015, 5325~5334
- S. Yang, P. Luo, C. C. Loy, X. Tang. From facial parts responses to face detection: A deep learning approach[C], IEEE International Conference on Computer Vision, 2015, 3676~3684